generation
Train Config Generation App.
The pyodi train-config generation
app can be used to automatically generate a mmdetection
anchor configuration to train your model.
The design of anchors is critical for the performance of one-stage detectors. Usually, published models such Faster R-CNN or RetinaNet include default anchors which has been designed to work with general object detection purpose as COCO dataset. Nevertheless, you might be envolved in different problems which data contains only a few different classes that share similar properties, as the object sizes or shapes, this would be the case for a drone detection dataset such Drone vs Bird. You can exploit this knowledge by designing anchors that specially fit the distribution of your data, optimizing the probability of matching ground truth bounding boxes with generated anchors, which can result in an increase in the performance of your model. At the same time, you can reduce the number of anchors you use to boost inference and training time.
Procedure
The input size parameter determines the model input size and automatically reshapes images and annotations sizes to it. Ground truth boxes are assigned to the anchor base size that has highest Intersection over Union (IoU) score with them. This step, allow us to locate each ground truth bounding box in a feature level of the FPN pyramid.
Once this is done, the ratio between the scales of ground truth boxes and the scales of
their associated anchors is computed. A log transform is applied to it and they are clustered
using kmeans algorithm, where the number of obtained clusters depends on n_scales input parameter.
After this step, a similar procedure is followed to obtain the reference scale ratios of the
dataset, computing log scales ratios of each box and clustering them with number of
clusters equal to n_ratios.
Example usage:
pyodi train-config generation \\
$TINY_COCO_ANIMAL/annotations/train.json \\
--input-size [1280,720] \\
--n-ratios 3 --n-scales 3
The app shows two different plots:
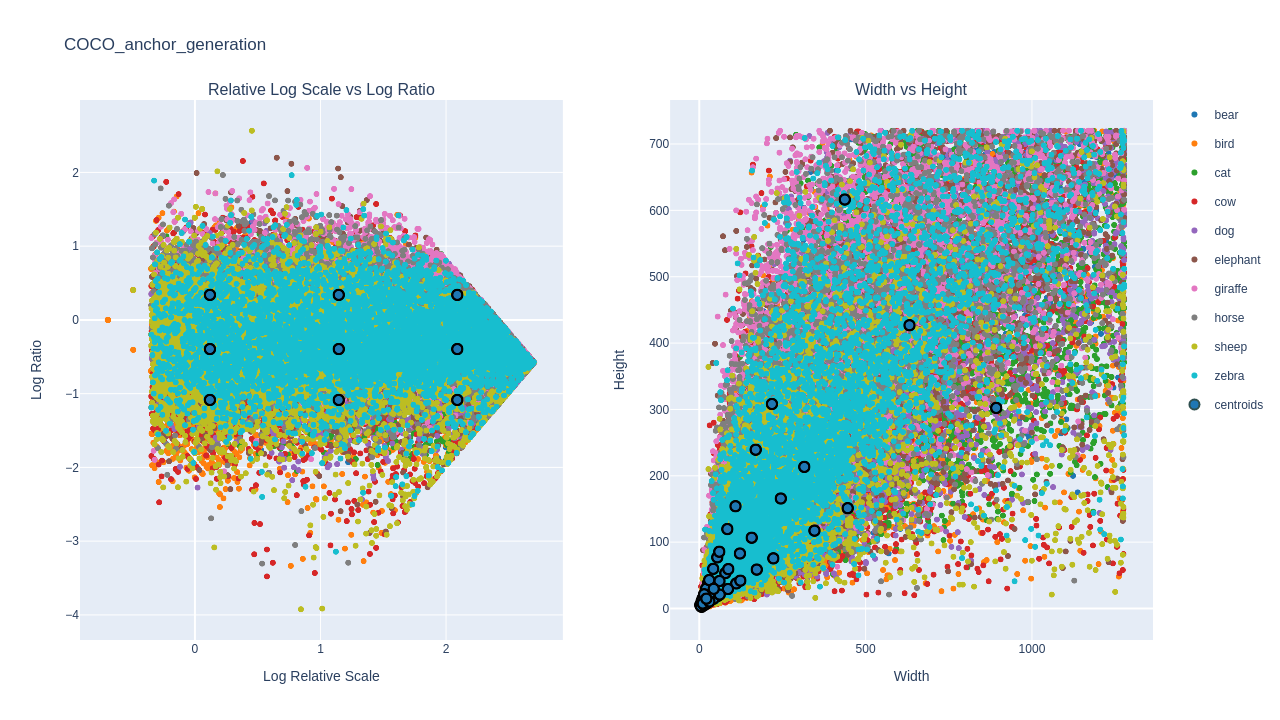
Log Relative Scale vs Log Ratio
In this graphic you can distinguish how your bounding boxes scales and ratios are distributed. The x axis represent the log scale of the ratio between the bounding box scales and the scale of their matched anchor base size. The y axis contains the bounding box log ratios. Centroids are the result of combinating the obtained scales and ratios obtained with kmeans. We can see how clusters appear in those areas where box distribution is more dense.
We could increase the value of n_ratios from three to four, having into account that
the number of anchors is goint to increase, which will influence training computational cost.
pyodi train-config generation annotations/train.json --input-size [1280,720] --n-ratios 4 --n-scales 3
In plot below we can observe the result for n_ratios equal to four.
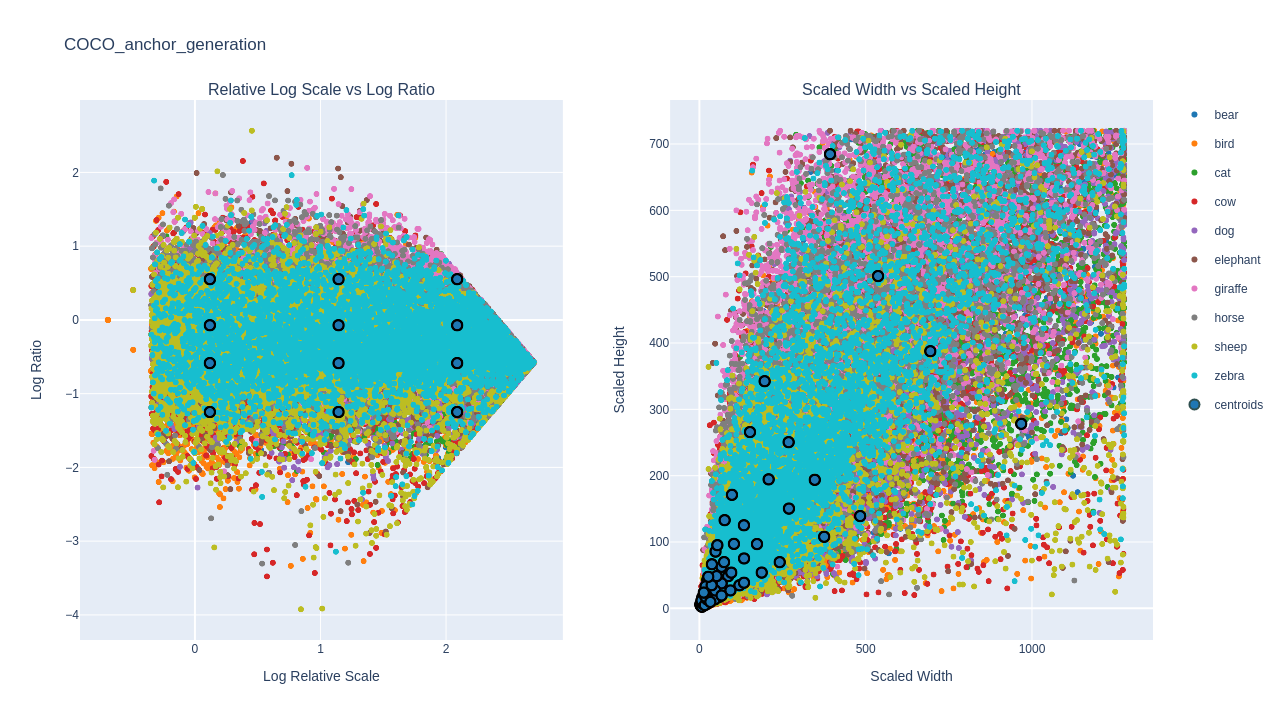
Bounding Box Distribution
This plot is very useful to observe how the generated anchors fit you bounding box distribution. The number of anchors depends on:
- The length of
base_sizeswhich determines the number of FPN pyramid levels. - A total of
n_ratiosxn_scalesanchors is generated per level
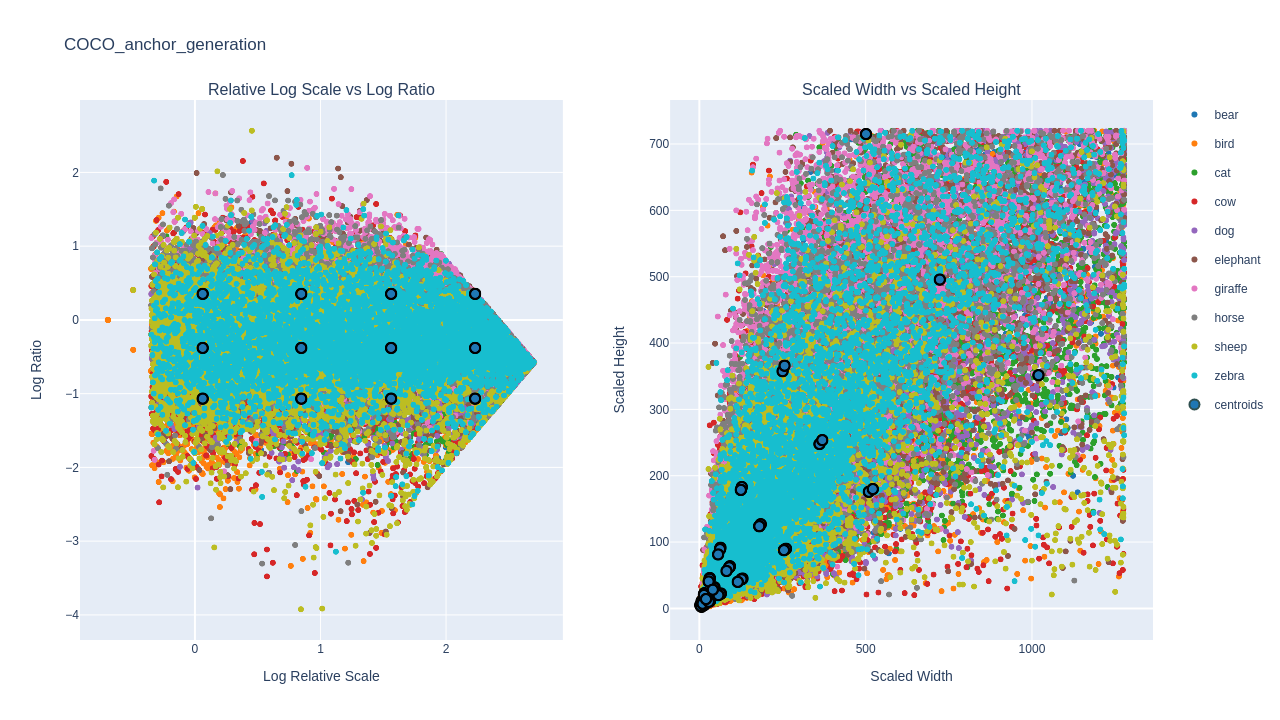
We can now increase the number of n_scales and observe the effect on the bounding box distribution plot.
Proposed anchors are also attached in a Json file that follows mmdetection anchors format:
anchor_generator=dict(
type='AnchorGenerator',
scales=[1.12, 3.13, 8.0],
ratios=[0.33, 0.67, 1.4],
strides=[4, 8, 16, 32, 64],
base_sizes=[4, 8, 16, 32, 64],
)
By default, pyodi train-config evaluation is
used after the generation of anchors in order to compare which generated anchor config suits better your data.
You can disable this evaluation by setting to False the evaluate argument, but it is strongly advised to
use the anchor evaluation module.
API REFERENCE
train_config_generation(ground_truth_file, input_size=(1280, 720), n_ratios=3, n_scales=3, strides=None, base_sizes=None, show=True, output=None, output_size=(1600, 900), keep_ratio=False, evaluate=True)
Computes optimal anchors for a given COCO dataset based on iou clustering.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
ground_truth_file |
str
|
Path to COCO ground truth file. |
required |
input_size |
Tuple[int, int]
|
Model image input size. Defaults to (1280, 720). |
(1280, 720)
|
n_ratios |
int
|
Number of ratios. Defaults to 3. |
3
|
n_scales |
int
|
Number of scales. Defaults to 3. |
3
|
strides |
Optional[List[int]]
|
List of strides. Defatults to [4, 8, 16, 32, 64]. |
None
|
base_sizes |
Optional[List[int]]
|
The basic sizes of anchors in multiple levels. If None is given, strides will be used as base_sizes. |
None
|
show |
bool
|
Show results or not. Defaults to True. |
True
|
output |
Optional[str]
|
Output directory where results going to be saved. Defaults to None. |
None
|
output_size |
Tuple[int, int]
|
Size of saved images. Defaults to (1600, 900). |
(1600, 900)
|
keep_ratio |
bool
|
Whether to keep the aspect ratio or not. Defaults to False. |
False
|
evaluate |
bool
|
Whether to evaluate or not the anchors. Check
|
True
|
Returns:
| Type | Description |
|---|---|
None
|
Anchor generator instance. |
Source code in pyodi/apps/train_config/train_config_generation.py
119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 | |